Dữ liệu lớn (Big Data) và một số thách thức đối với phân tích dữ liệu lớn
Tóm tắt: Cùng với sự phát triển của khoa học và công nghệ, sự sẵn có của lượng dữ liệu khổng lồ trên Internet đã thu hút sự chú ý lớn từ các nhà nghiên cứu trong nhiều lĩnh vực như khoa học dữ liệu, ra quyết định, ứng dụng trong kinh doanh, y tế, giáo dục … thậm chí là cả chính phủ. Những lượng dữ liệu khổng lồ được gọi là dữ liệu lớn này thường có giá trị tiềm tàng rất lớn và là mục tiêu khai phá, phân tích của nhiều nghiên cứu và ứng dụng thực tế. Tuy nhiên, việc tổ chức lưu trữ, xử lý và phân tích các tập dữ liệu lớn sẽ tiêu tốn rất nhiều thời gian do độ phức tạp tính toán lớn và đặt ra các yêu cầu rất cao về các nền tảng phần cứng, phần mềm với các kỹ thuật hỗ trợ tiên tiến. Trên cơ sở tham khảo bài báo của Abdalla (2022) và các tài liệu liên quan, bài viết này sẽ trình bày một số vấn đề tổng quan về dữ liệu lớn và các thách thức đối với phân tích dữ liệu lớn.
Từ khóa: dữ liệu lớn, phân tích dữ liệu, các thách thức
- Đặt vấn đề
Dữ liệu lớn đã trở thành chủ đề nghiên cứu mới và nổi bật nhất nhờ sự sẵn có, giá trị to lớn, khả năng sử dụng và ứng dụng rộng rãi của chúng trong nhiều lĩnh vực khác nhau [1]. Từ năm 2013, theo Gartner, dữ liệu lớn đã được dự đoán sẽ nổi bật trong số các công nghệ mới và được liệt vào danh sách các công nghệ có xu hướng dẫn đầu giai đoạn 2013-2018. Sau đó, theo Tập đoàn Dữ liệu Quốc tế (IDC – International Data Corporation), thị trường đổi mới dữ liệu lớn đã tạo ra khoảng 32,4 tỷ USD vào năm 2017. Ngày nay, với sự phát triển nhanh chóng của khoa học và công nghệ, các kỹ thuật khai thác dữ liệu và khai thác thông tin khác nhau, tính toán dựa trên trí tuệ nhân tạo (AI -Artificial Intelligence) cũng như các hệ thống và công cụ nguồn mở, nhiều tập dữ liệu lớn đã được tạo ra và được truy cập bởi người dùng. Khả năng truy cập vào các bộ dữ liệu lớn này để sử dụng trong các ứng dụng dữ liệu lớn yêu cầu xử lý dữ liệu và quản trị ứng dụng hiệu quả đã mở rộng đáng kể phạm vi đáp ứng các nhu cầu nghiệp vụ và nhu cầu cá nhân thường ngày.
Việc lưu trữ, xử lý, phân tích dữ liệu lớn hiện được sử dụng trong hầu hết các khung (framework) ứng dụng, như khung gợi ý, dự báo, nhận dạng mẫu, … sử dụng trong nhiều lĩnh vực khác nhau như kinh tế, chính trị, giáo dục, y tế, tài nguyên môi trường, khoa học đời sống, … Ví dụ: Bộ phận nghiên cứu thị trường của một công ty có thể nắm bắt được nhu cầu, thị hiếu của người tiêu dùng dựa trên cơ sở thu thập và phân tích lượng dữ liệu khổng lồ về các từ khóa tìm kiếm sản phẩm trên các công cụ tìm kiếm trực tuyến.
Mặc dù đã có những tiến bộ trong việc lưu trữ, xử lý và phân tích dữ liệu lớn, nhưng do khối lượng dữ liệu khổng lồ được tạo ra với tốc độ nhanh và sự không đồng nhất dữ liệu, các ứng dụng dựa trên dữ liệu lớn vẫn gặp phải những khó khăn nhất định đặc biệt là về vấn đề đảm bảo chất lượng. Việc phê duyệt chất lượng dữ liệu lớn và xác nhận chất lượng khung ứng dụng dựa trên dữ liệu lớn cần được quan tâm và xem xét thêm. Bên cạnh đó, ngày càng có nhiều mối lo ngại về việc sử dụng thông tin cá nhân không đúng mục đích, đặc biệt khi các thông tin đó được tổng hợp lại từ nhiều nguồn khác nhau. Do đó, vấn đề bảo mật và quyền riêng tư cũng cần được xem xét khi khai thác các nguồn dữ liệu lớn.
Bài viết này sẽ trình bày một số vấn đề tổng quan về dữ liệu lớn và các thách thức đối với phân tích dữ liệu lớn.
- Dữ liệu lớn và các đặc trưng chính
Dữ liệu lớn (Big Data) là tập dữ liệu quá lớn hoặc quá phức tạp mà các nền tảng lưu trữ, xử lý và phân tích dữ liệu truyền thống không đáp ứng được. Chúng thường được tạo ra/tổng hợp từ nhiều nguồn khác nhau, gồm nhiều dạng dữ liệu khác nhau (cấu trúc, bán cấu trúc, phi cấu trúc). Hầu hết các nhà nghiên cứu và chuyên gia mô tả dữ liệu lớn bằng 5 đặc trưng điển hình, được gọi là 5V: vận tốc, sự đa dạng, giá trị, tính xác thực và khối lượng [3].
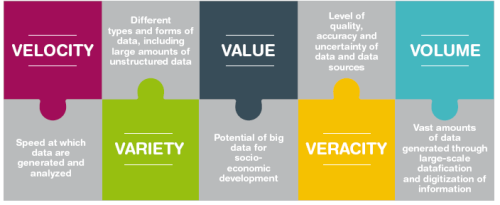
Nguồn: Trần Việt Trung, 2021
- Vận tốc (Volumn):
Vận tốc được xem xét ở đây là tốc độ dữ liệu được tạo ra, di chuyển và phân tích. Việc phát minh ra các thiết bị tiên tiến, như thiết bị PDA (Personal Digital Assistants) và các cảm biến đã thúc đẩy tốc độ sản xuất dữ liệu nhanh chóng và thúc đẩy nhu cầu ngày càng tăng về nghiên cứu, phân tích, khai thác dữ liệu lớn. Ví dụ, trên hệ thống bán hàng trực tuyến của tập đoàn bán lẻ hàng đầu thế giới Wal-Mart ghi nhận hơn 1.000.000 giao dịch mỗi giờ. Dữ liệu chi tiết về khách hàng như khu vực địa lý, kinh tế xã hội và hành vi mua hàng trong quá khứ, … có thể được thu thập, phân tích liên tục để nắm bắt nhu cầu của khách hàng và đề xuất các gợi ý phù hợp.
- Sự đa dạng (Variety):
Sự đa dạng được định nghĩa là sự đa dạng hóa về mặt kiến trúc trong một tập dữ liệu. Dữ liệu lớn thường chứa đựng dữ liệu thuộc nhiều kiểu (type)/hình thức (form) khác nhau, bao gồm cả dữ liệu có cấu trúc (structured), bán cấu trúc (semi-structured) và phi cấu trúc (unstructured). Dữ liệu có cấu trúc thường bao gồm các phần tử dữ liệu được tổ chức theo một cấu trúc xác định nhờ đó dễ dàng xử lý, khai thác chúng. Ví dụ: Dữ liệu trong một cơ sở dữ liệu tuân theo mô hình quan hệ được tổ chức thành các bảng gồm các cột và các dòng. Dữ liệu bán cấu trúc không tuân theo một lược đồ tổ chức hay một mô hình dữ liệu nghiêm ngặt song vẫn có cấu trúc ở một mức độ nhất định. Chúng thường được đặc trưng bởi việc sử dụng siêu dữ liệu (metadata) hoặc các thẻ cung cấp thông tin bổ sung về các thành phần dữ liệu. Ví dụ: Một tài liệu XML có thể chứa các thẻ cho biết cấu trúc của tài liệu và cũng có thể chứa các thẻ bổ sung cung cấp siêu dữ liệu về nội dung như tác giả, ngày tháng hoặc từ khóa. Dữ liệu phi cấu trúc là dữ liệu không được tổ chức theo cách được xác định trước hoặc không tuân theo mô hình dữ liệu cụ thể. Ví dụ: Các bài viết đăng trên các diễn đàn hoặc trang cá nhân.
- Tính xác thực (Veracity):
Tính xác thực cho biết mức độ chất lượng (quality), độ chính xác (accuracy) và tính không chắc chắn (uncertainty) của dữ liệu được thu thập từ nhiều nguồn khác nhau.
- Giá trị (Value):
Phản ánh giá trị tiềm năng mà dữ liệu cung cấp. Dữ liệu lớn có giá trị cao đồng nghĩa với lượng tri thức thu được từ dữ liệu nhiều và có giá trị, phục vụ tốt cho việc giải quyết các bài toán thực tế.
- Khối lượng (Volume):
Dữ liệu lớn thường bao gồm một lượng dữ liệu khổng lồ được sinh ra thông qua việc dữ liệu hóa và số hóa thông tin với quy mô lớn. Lượng dữ liệu lớn được đo bằng các đơn vị như terabyte, petabyte, exabyte, zettabyte hay thậm chí là yottabyte. Một đánh giá do tổ chức quốc tế International Business Machines Corporation (IBM) thực hiện vào năm 2012 cho thấy phần lớn những người được phỏng vấn coi các tập dữ liệu lớn hơn 1 terabyte là tập dữ liệu lớn, theo đó 1 terabyte lưu trữ được lượng thông tin tương đương với 220 đĩa DVD hoặc 1500 đĩa CD – đủ để lưu trữ tới 16 triệu hình ảnh trên Facebook. Tuy nhiên, rất khó xác định một giới hạn cụ thể để kết luận một tập dữ liệu là lớn. Trong thực tế, chúng chỉ được ước lượng một cách tương đối tùy thuộc từng loại dữ liệu, nguồn cung cấp dữ liệu, mục đích sử dụng dữ liệu, … cụ thể và có thể bị thay đổi theo thời gian.
- Phân tích trực quan trong dữ liệu lớn
Phân tích trực quan (VA – Visual analytics) tập trung vào việc hỗ trợ tương tác và khám phá trong việc phân tích dữ liệu lớn, phức tạp. Phân tích trực quan dữ liệu lớn phụ thuộc vào ba tầng chính: tầng trực quan hóa, tầng phân tích và tầng quản lý dữ liệu.
- Trực quan hóa (Visualization):
Thuật ngữ trực quan hóa được định nghĩa là việc sử dụng biểu diễn trực quan chung của dữ liệu khái niệm để tăng cường nhận thức. Chức năng và hình thức thẩm mỹ là cần thiết để truyền tải thông tin dễ dàng. Thông tin như các biến và các thuộc tính được trừu tượng hóa từ dữ liệu ở dạng ngữ nghĩa. Trực quan hóa dữ liệu lớn là một quá trình phức tạp do tính đa chiều và kích thước lớn của dữ liệu, vì vậy cần xem xét, sử dụng các kỹ thuật, công cụ thích hợp.
- Phân tích (Analytics):
Phân tích được định nghĩa là quá trình thu thập các kết luận từ dữ liệu lớn thông qua việc đánh giá dữ liệu. Các nhà nghiên cứu áp dụng một số phương pháp xử lý trong quá trình đánh giá để đạt được kết quả tốt hơn. Nếu dữ liệu nhỏ, việc xem xét có thể được thực hiện nhanh chóng và dữ liệu được trực quan hóa bằng cách sử dụng tiện ích biểu đồ. Do đó, việc tích hợp môi trường phân tích với môi trường trực quan được sử dụng rộng rãi trong các ngành công nghiệp và nghiên cứu. Nếu dữ liệu quá lớn, việc tích hợp trực quan hóa và phân tích có thể không hoạt động tốt và có thể tạo ra các vấn đề về tính khả mở.
- Quản lý dữ liệu (Data management):
Quản lý dữ liệu là một khía cạnh quan trọng của ứng dụng VA vì nó giúp quản lý vòng đời của dữ liệu. Quản lý dữ liệu góp phần đảm bảo chất lượng, truy xuất dữ liệu và bảo trì dữ liệu theo thời gian. Các công cụ quản lý dữ liệu thông thường không thể xử lý được dữ liệu lớn với kích thước lớn và phức tạp.
- Một số công cụ dữ liệu lớn
Việc phân tích dữ liệu lớn đóng một vai trò quan trọng trong quá trình ra quyết định. Rất nhiều công cụ phân tích dữ liệu lớn đã được phát triển nhằm hỗ trợ các chuyên gia trong việc lưu trữ, quản lý, lọc, khai phá, dự báo và chứng thực dữ liệu.
- NoSQL[i]:
Thông thường, SQL (Structured Query Language – ngôn ngữ truy vấn có cấu trúc) được sử dụng rộng rãi để kiểm soát và phân tích dữ liệu có cấu trúc. Tuy nhiên, dữ liệu không xác định đã tiến triển mạnh bắt nguồn từ sự phát triển của các bộ máy phân tích thông tin phi cấu trúc. Cuối cùng, NoSQL đã xuất hiện để xử lý hiệu quả các mô hình dữ liệu không được tổ chức. Các cơ sở dữ liệu NoSQL không tuân theo một kiến trúc định trước khi lưu trữ dữ liệu không xác định. Do tính chất không có kiến trúc này, hệ thống cân bằng tính nhất quán, khả năng thích ứng với lỗi bên trong và khả năng truy cập.
Cơ sở dữ liệu NoSQL có nhiều loại khác nhau, trong đó 4 loại chính gồm: document (tài liệu), key-value (khóa-giá trị), wide-column (cột rộng) và graph (đồ thị). Chúng cung cấp các lược đồ linh hoạt và mở rộng quy mô một cách dễ dàng với lượng dữ liệu lớn và lượng người dùng cao.
- Document: lưu trữ dữ liệu trong các tài liệu tương tự như các đối tượng JSON. Mỗi tài liệu chứa các cặp trường (field) và giá trị (value). Các giá trị thường có thể có nhiều loại khác nhau, như chuỗi, số, boolean, mảng hoặc đối tượng.
- Key-value: là loại cơ sở dữ liệu đơn giản hơn trong đó mỗi mục chứa khóa và giá trị.
- Wide-column: lưu trữ dữ liệu trong các bảng, hàng và các cột động.
- Graph: lưu trữ dữ liệu trong các nút và các cạnh. Các nút thường lưu trữ thông tin về con người, địa điểm, sự vật, trong khi các cạnh lưu trữ thông tin về mối quan hệ giữa các nút.
Cơ sở dữ liệu NoSQL rất phù hợp với nhiều ứng dụng hiện đại như thiết bị di động, web và trò chơi – yêu cầu các cơ sở dữ liệu linh hoạt, khả mở, có hiệu suất cao và tính ứng dụng cao để mang lại trải nghiệm tuyệt vời cho người dùng.
- Tính linh hoạt (Flexibility): Cơ sở dữ liệu NoSQL thường cung cấp các lược đồ linh hoạt cho phép phát triển nhanh và lặp lại nhiều hơn. Mô hình dữ liệu linh hoạt làm cho cơ sở dữ liệu NoSQL trở nên lý tưởng cho dữ liệu bán cấu trúc và phi cấu trúc.
- Tính khả mở (Scalability): Cơ sở dữ liệu NoSQL thường được thiết kế để mở rộng quy mô bằng cách sử dụng các cụm phần cứng phân tán thay vì mở rộng quy mô bằng cách thêm các máy chủ cấu hình mạnh và đắt tiền. Một số nhà cung cấp cloud xử lý các hoạt động hậu trường này dưới dạng dịch vụ được quản lý hoàn toàn.
- Hiệu suất cao (High-performance): Cơ sở dữ liệu NoSQL được tối ưu hóa cho các mô hình dữ liệu và mẫu truy cập cụ thể mang lại hiệu suất cao hơn so với việc cố gắng đạt được chức năng tương tự với cơ sở dữ liệu quan hệ.
- Có tính ứng dụng cao (Highly functional): Cơ sở dữ liệu NoSQL cung cấp các API và kiểu dữ liệu có tính ứng dụng cao được xây dựng có mục đích cho từng mô hình dữ liệu tương ứng của chúng.
- Cassandra[ii]:
Cassandra là một cơ sở dữ liệu phân tán dạng NoSQL. Theo thiết kế, cơ sở dữ liệu NoSQL có thiết kế nhỏ gọn, tối ưu, nguồn mở, phi quan hệ và phân tán rộng rãi. Điểm mạnh của chúng là ở mức độ lỗi thấp, đảm bảo khả năng truy cập cao trong mọi điều kiện, khả năng mở rộng theo chiều ngang, kiến trúc phân tán và cách tiếp cận linh hoạt để định nghĩa lược đồ. Ngoài ra, Cassandra cho phép sao chép thông tin trên nhiều cloud khác nhau hoặc các cụm máy chủ để đảm bảo thời gian ngủ đông thấp hơn và khả năng thích ứng cao với lỗi nội bộ.
Cơ sở dữ liệu NoSQL cho phép tổ chức và phân tích nhanh chóng, đặc biệt là các loại dữ liệu khác nhau với khối lượng dữ liệu cực lớn. Điều đó trở nên quan trọng hơn với sự ra đời của dữ liệu lớn và nhu cầu mở rộng nhanh chóng cơ sở dữ liệu trên cloud trong những năm gần đây. Cassandra là một trong những cơ sở dữ liệu NoSQL đã giải quyết được các hạn chế của các công nghệ quản lý dữ liệu trước đây, chẳng hạn như cơ sở dữ liệu SQL.
- Hadoop:[iii]
Hadoop là một hệ thống bao gồm nhiều loại thư viện lập trình, tích hợp các mô hình lập trình khác nhau để cho phép tính toán, xử lý phân tán trên các tập dữ liệu khổng lồ. Nó được thiết kế để mở rộng quy mô từ các máy chủ đơn lẻ lên đến hàng nghìn máy, mỗi máy cung cấp khả năng tính toán và lưu trữ cục bộ. Thay vì dựa vào phần cứng để mang lại tính sẵn sàng cao, bản thân các thư viện được thiết kế để phát hiện và xử lý các lỗi ở lớp ứng dụng, do đó cung cấp dịch vụ có tính sẵn sàng cao trên một cụm máy tính mà ở đó mỗi máy tính đều có thể dễ bị lỗi. Hệ thống Hadoop bao gồm các module:
- Hadoop Common: Cung cấp các thư viện Java phổ biến có thể được sử dụng trên tất cả các mô-đun Hadoop khác.
- Hệ thống tệp phân tán Hadoop (HDFS – Hadoop Distributed File System): Một hệ thống tệp phân tán chạy trên phần cứng tiêu chuẩn hoặc cấp thấp. HDFS cung cấp thông lượng dữ liệu tốt hơn các hệ thống tệp truyền thống, bên cạnh khả năng chịu lỗi cao và hỗ trợ riêng cho các bộ dữ liệu lớn.
- Hadoop YARN (Yet Another Resource Negotiator): Quản lý và giám sát các nút cụm cũng như việc sử dụng tài nguyên. Nó lập lịch công việc và các tác vụ.
- Hadoop MapReduce: Một hệ thống dựa trên YARN để xử lý song song các tập dữ liệu lớn. Tác vụ Map lấy dữ liệu đầu vào và chuyển đổi nó thành tập dữ liệu có thể được tính toán theo cặp khóa-giá trị. Đầu ra của tác vụ Map được sử dụng bởi các tác vụ Reduce để tổng hợp đầu ra và cung cấp kết quả mong muốn.
- Storm:[iv]
Apache Storm là một hệ thống tính toán thời gian thực phân tán mã nguồn mở và miễn phí. Apache Storm giúp dễ dàng xử lý các luồng dữ liệu không giới hạn một cách đáng tin cậy, thực hiện xử lý theo thời gian thực những gì mà Hadoop đã làm để xử lý theo lô. Apache Storm rất đơn giản, có thể được sử dụng với bất kỳ ngôn ngữ lập trình nào và rất thú vị khi sử dụng!
Apache Storm có nhiều trường hợp sử dụng: phân tích thời gian thực, học máy trực tuyến, tính toán liên tục, RPC phân tán, ETL, … Apache Storm rất nhanh: điểm chuẩn đạt tốc độ hơn một triệu bộ dữ liệu được xử lý mỗi giây tại mỗi nút. Nó có khả năng mở rộng (khả mở), có khả năng chịu lỗi, đảm bảo dữ liệu sẽ được xử lý và dễ cài đặt cũng như vận hành.
Apache Storm tích hợp với các công nghệ cơ sở dữ liệu và hàng đợi. Cấu trúc liên kết (topology) Apache Storm sử dụng các luồng dữ liệu và xử lý các luồng đó theo những cách phức tạp tùy ý, phân vùng lại các luồng giữa mỗi giai đoạn tính toán theo cách cần thiết.
- Spark:[v]
Spark là một hệ thống xử lý phân tán, mã nguồn mở được sử dụng cho các Big data workload, cho phép thực thi các kỹ thuật dữ liệu, khoa học dữ liệu và học máy trên các máy đơn hoặc các cụm. Nó sử dụng bộ nhớ đệm và thực hiện truy vấn được tối ưu hóa để truy vấn phân tích nhanh đối với dữ liệu ở mọi kích thước. Nó cung cấp các API phát triển bằng Java, Scala, Python và R, đồng thời hỗ trợ tái sử dụng mã trên nhiều workload – xử lý lô, truy vấn tương tác, phân tích thời gian thực, học máy và xử lý đồ họa.
Các tính năng chính của Spark:
- Dữ liệu theo lô/luồng (Batch/streaming data): Thống nhất việc xử lý dữ liệu theo lô và luồng thời gian thực, sử dụng các ngôn ngữ phổ biến: Python, SQL, Scala, Java hoặc R.
- Phân tích SQL (SQL analytics): Thực thi nhanh các truy vấn ANSI SQL phân tán để lập trang tổng quan (dashboard) và các báo cáo đặc biệt. Spark chạy nhanh hơn hầu hết các kho dữ liệu.
- Khoa học dữ liệu ở quy mô lớn (Data science at scale): Thực hiện Phân tích dữ liệu thăm dò (EDA – Exploratory Data Analysis) trên dữ liệu ở quy mô petabyte mà không cần phải sử dụng phương pháp lấy mẫu xuống (downsampling).
- Học máy (Machine learning): Huấn luyện các thuật toán học máy trên máy tính xách tay và sử dụng cùng một mã để mở rộng quy mô thành các cụm có khả năng chịu lỗi gồm hàng nghìn máy.
Spark framework gồm:
- Spark core làm nền móng. Nó chịu trách nhiệm quản lý bộ nhớ, phục hồi lỗi, lập lịch, phân phối và giám sát công việc cũng như tương tác với các hệ thống lưu trữ. Spark Core được thể hiện thông qua giao diện lập trình ứng dụng (API) được xây dựng cho Java, Scala, Python và R. Các API này che giấu sự phức tạp của quá trình xử lý phân tán đằng sau các operator đơn giản hoặc cao cấp.
- Spark SQL cho các truy vấn tương tác. Là một công cụ truy vấn phân tán cung cấp các truy vấn tương tác, độ trễ thấp, nhanh hơn tới 100 lần so với MapReduce. Nó bao gồm trình tối ưu hóa dựa trên chi phí, lưu trữ theo cột và sinh mã cho các truy vấn nhanh, đồng thời có khả năng mở rộng tới hàng nghìn nút. Các nhà phân tích nghiệp vụ có thể sử dụng SQL tiêu chuẩn hoặc ngôn ngữ truy vấn Hive để truy vấn dữ liệu. Các nhà phát triển có thể sử dụng các API có sẵn trong Scala, Java, Python và R. Nó hỗ trợ nhiều nguồn dữ liệu có sẵn khác nhau, bao gồm JDBC, ODBC, JSON, HDFS, Hive, ORC và Parquet. Các kho lưu trữ phổ biến như: Amazon Redshift, Amazon S3, Couchbase, Cassandra, MongoDB, Salesforce.com, Elasticsearch và nhiều kho khác có thể được tìm thấy từ hệ sinh thái Spark Packages.
- Spark Streaming cho phân tích theo thời gian thực. Là giải pháp thời gian thực tận dụng khả năng lập lịch nhanh của Spark Core để thực hiện phân tích theo luồng. Nó nhập dữ liệu theo các lô nhỏ và cho phép phân tích dữ liệu đó với cùng mã ứng dụng được viết cho các phân tích theo lô. Điều này cải thiện năng suất của nhà phát triển vì họ có thể sử dụng cùng một mã cho xử lý theo lô và cho các ứng dụng theo luồng thời gian thực. Spark Streaming hỗ trợ dữ liệu từ Twitter, Kafka, Flume, HDFS và ZeroMQ cũng như nhiều dữ liệu khác được tìm thấy từ hệ sinh thái Spark Packages.
- Spark MLlib cho học máy. Đây là một thư viện thuật toán để thực hiện học máy trên dữ liệu ở quy mô lớn. Các nhà khoa học dữ liệu có thể huấn luyện các mô hình học máy bằng R hoặc Python trên bất kỳ nguồn dữ liệu Hadoop nào, được lưu bằng MLlib và được nhập vào quy trình dựa trên Java hoặc Scala. Spark được thiết kế để tính toán tương tác, nhanh, chạy trong bộ nhớ, cho phép chạy các mô hình học máy một cách nhanh chóng. Các thuật toán được sử dụng bao gồm phân loại, hồi quy, phân cụm, lọc cộng tác và khai thác mẫu.
- Spark GraphX cho xử lý đồ họa. Spark GraphX là một framework xử lý đồ họa phân tán được xây dựng dựa trên Spark. GraphX cung cấp ETL, phân tích thăm dò và tính toán đồ họa tương tác cho phép người dùng xây dựng và chuyển đổi tương tác một cấu trúc dữ liệu đồ họa ở quy mô lớn. Nó đi kèm với một API linh hoạt cao và một loạt các thuật toán đồ họa phân tán.
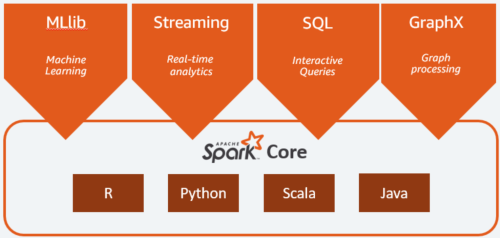
Nguồn: https://aws.amazon.com/
- Hive[vi]:
Hive là một hệ thống kho dữ liệu được sử dụng để truy vấn và phân tích các tập dữ liệu lớn được lưu trữ trong HDFS (Hadoop Distributed File System – Hệ thống tệp phân tán Hadoop). Hive sử dụng ngôn ngữ truy vấn HiveQL – tương tự như SQL. Khi người dùng gửi các truy vấn Hive, các truy vấn này được chuyển đổi thành các tác vụ MapReduce và truy cập vào hệ thống MapReduce của Hadoop.

Nguồn: https://www.simplilearn.com/
Kiến trúc của Hive được chỉ ra như trong hình dưới đây:

Nguồn: https://www.simplilearn.com/
Bắt đầu từ Hive Client – có thể là các lập trình viên có khả năng sử dụng thành thạo SQL để tra cứu dữ liệu cần thiết. Hive Client hỗ trợ các loại ứng dụng client khác nhau bằng các ngôn ngữ khác nhau để thực hiện truy vấn. Thrift là một khung phần mềm. Máy chủ Hive dựa trên Thrift, vì vậy nó có thể phục vụ các yêu cầu từ tất cả các ngôn ngữ lập trình hỗ trợ Thrift. Tiếp theo là ứng dụng JDBC (Java Database Connectivity) và Hive JDBC driver. Ứng dụng JDBC được kết nối thông qua JDBC driver. Sau đó là một ứng dụng ODBC (Open Database Connectivity) được kết nối thông qua ODBC driver. Tất cả các yêu cầu client được gửi đến Hive server.
Giao diện web Hive hoặc GUI, nơi các lập trình viên thực hiện các truy vấn Hive. Các lệnh được thực thi trực tiếp trong CLI. Tiếp theo là Hive driver, chịu trách nhiệm về tất cả các truy vấn được gửi. Nó thực hiện ba bước nội bộ:
- Biên dịch – Hive driver chuyển truy vấn đến trình biên dịch, nơi nó được kiểm tra và phân tích.
- Tối ưu hóa – Thu được sơ đồ logic được tối ưu hóa dưới dạng biểu đồ các tác vụ MapReduce và HDFS.
- Thực thi – Ở bước cuối cùng, các tác vụ được thực thi.
Metastore là kho lưu trữ siêu dữ liệu Hive. Nó lưu trữ siêu dữ liệu cho các bảng Hive và có thể xem như là các lược đồ. Nó nằm trên Apache Derby DB. Hive sử dụng khung MapReduce để xử lý các truy vấn. Cuối cùng, là bộ lưu trữ phân tán – HDFS. Chúng nằm trên các máy thông dụng và có khả năng mở rộng tuyến tính.
- OpenRefine[vii]:
OpenRefine là một công cụ rất mạnh dạng nguồn mở để làm việc với dữ liệu lộn xộn, cho phép làm sạch dữ liệu, chuyển đổi dữ liệu từ định dạng này sang định dạng khác và mở rộng dữ liệu với các dịch vụ web và dữ liệu bên ngoài. 6 tính năng nổi bật của OpenRefine gồm:
– Cắt mặt (Faceting): Đi sâu vào các tập dữ liệu lớn bằng cách sử dụng các mặt cắt (facet) và áp dụng các thao tác trên các chế độ xem được lọc của tập dữ liệu.
– Phân cụm (Clustering): Cho phép khắc phục sự không nhất quán bằng cách hợp nhất các giá trị tương đồng nhờ phương pháp phỏng đoán mạnh mẽ.
– Đối chiếu (Reconciliation): Cho phép so khớp tập dữ liệu với cơ sở dữ liệu bên ngoài thông qua các dịch vụ đối chiếu.
– Hoàn tác/làm lại (Undo/redo): Cho phép quay lại bất kỳ trạng thái nào trước đó của tập dữ liệu và lặp lại các hoạt động trong lịch sử trên phiên bản mới của tập dữ liệu đó.
– Bảo mật (Privacy): Làm sạch dữ liệu trên máy cá nhân chứ không phải trên cloud.
– Wikibase: Đóng góp cho Wikidata – cơ sở dữ liệu thứ cấp, đa ngôn ngữ, cộng tác và miễn phí – và các phiên bản Wikibase khác.

Nguồn: https://openrefine.org
- Phân tích dữ liệu lớn: các vấn đề và thách thức
Dữ liệu lớn đang gặp nhiều khó khăn trong việc quản lý tổ chức. Khung làm việc với dữ liệu lớn cần hiểu được yêu cầu của dữ liệu lớn và yêu cầu của khách hàng. Hiện nay, khối lượng thông tin đang tăng lên từng ngày và tốc độ phát triển của nó đang tăng nhanh hơn bao giờ hết trong lịch sử; do đó rất khó để giải quyết những khó khăn mà dữ liệu lớn mang lại. Các công cụ, kỹ thuật, cải tiến và phương pháp điều tra hiện tại không thể theo kịp mức độ phức tạp của thông tin được đưa ra. Một số khó khăn chung được mô tả như dưới đây:
- Bảo vệ, bảo mật và sự tín nhiệm: Các tổ chức sử dụng dữ liệu lớn cần đảm bảo sự bảo vệ và bảo mật dữ liệu cho khách hàng của mình. Sự tín nhiệm của khách hàng đối với các tổ chức này và khả năng lưu giữ dữ liệu của một cá nhân một cách an toàn chắc chắn sẽ bị ảnh hưởng nếu thông tin hoặc dữ liệu bị rò rỉ vào miền công cộng.
- Quản lý và chia sẻ thông tin: Để thông tin có giá trị, nó cần khám phá được, mở và sử dụng được. Các tổ chức quản lý dữ liệu lớn cần đáp ứng được những yêu cầu cần thiết này, đặc biệt là yêu cầu thông tin mở (các bộ dữ liệu cần truy cập được đối với xã hội nói chung) nhưng vẫn phải tuân thủ luật an ninh.
- Khả năng đổi mới và phân tích: phân tích dữ liệu lớn đặt trọng tâm vào các nhà cung cấp Công nghệ thông tin và truyền thông (ICT) trong việc phát triển các thiết bị, công nghệ và kỹ thuật mới để xử lý hiệu quả lượng thông tin phức tạp khổng lồ. Các công cụ và cải tiến hiện tại vẫn chưa giải quyết triệt để được yêu cầu này.
Một số vấn đề và thách thức cụ thể của phân tích dữ liệu lớn:
- Lưu trữ và truy xuất thông tin: hiện tại, những kỹ thuật tiên tiến có thể lưu trữ, truy cập, xử lý các phần thông tin. Tuy nhiên, các bộ máy dự kiến cho quá trình trao đổi có thể tìm kiếm một lượng nhỏ dữ liệu thay vì một lượng thông tin khổng lồ. Phương pháp hiệu quả nhất để xử lý thông tin bán cấu trúc hoặc phi cấu trúc vẫn chưa được làm rõ.
- Tăng trưởng và mở rộng thông tin: Thông tin của các tổ chức có thể thường xuyên tăng trưởng và mở rộng theo thời gian, đặc biệt là khi có sự thay đổi, nâng cấp chiến lược của tổ chức.
- Tốc độ và quy mô: Rất khó để đạt được hiểu biết từ thông tin khi khối lượng dữ liệu ngày càng tăng. Việc đạt được hiểu biết về thông tin được ưu tiên hơn việc xử lý toàn bộ sự sắp xếp thông tin. Việc tính toán gần với thông tin liên tục sẽ luôn yêu cầu phải chuẩn bị kỹ càng để tạo ra kết quả có thể chấp nhận được.
- Thông tin có tổ chức và thông tin phi cấu trúc: sự chuyển đổi giữa thông tin có tổ chức được lưu trữ trong các bảng rõ ràng và thông tin phi cấu trúc (hình ảnh, bản ghi âm, văn bản) cần phải được kiểm tra và sẽ ảnh hưởng đến việc chuẩn bị thông tin từ đầu đến cuối. Việc mô tả và tính toán thông tin sẽ trở nên dễ thích ứng hơn với sự phát triển của dữ liệu phi quan hệ mới.
- Quyền sở hữu thông tin: lượng thông tin rất lớn nằm trong tay nhân viên của các tổ chức chuyên trách về truyền thông dựa trên web. Họ không sở hữu thông tin này; tuy nhiên, họ lưu trữ thông tin về các khách hàng của họ. Chủ sở hữu thực sự của trang đã tạo ra trang hoặc bản ghi. Quyền sở hữu thông tin là một thách thức ngày càng tăng trong miền truyền thông trực tuyến.
- Độ lệch dữ liệu: trong một tập dữ liệu, sự phân bố dữ liệu không đồng đều được gọi là độ lệch dữ liệu, chỉ hợp lệ trong kiến trúc xử lý song song nơi diễn ra xử lý dữ liệu phân tán. Tầm quan trọng của xử lý dữ liệu phân tán là thay vì một bộ xử lý duy nhất thực hiện một công việc, nếu công việc này được chia thành nhiều công việc song song nhỏ hơn được xử lý bởi các bộ xử lý khác nhau thì toàn bộ công việc đó sẽ được hoàn thành nhanh hơn. Điều này làm giảm thời gian thực hiện và cải thiện hiệu suất.
- Tính đa dạng của dữ liệu: một trong những đặc trưng quan trọng của Big Data là tính đa dạng của dữ liệu. Việc kết hợp dữ liệu từ nhiều nguồn và phân tán dữ liệu theo những cách khác nhau sẽ dẫn đến sự đa dạng của dữ liệu. Việc sử dụng các tài nguyên xử lý, chẳng hạn như sử dụng CPU, rất khác nhau do đặc trưng này của dữ liệu lớn.
- Tài nguyên bị hạn chế: điện toán biên (edge computing) là mô hình điện toán phân tán giúp đưa tính toán và lưu trữ dữ liệu đến gần hơn với các nguồn dữ liệu. Nó được kỳ vọng sẽ cải thiện thời gian phản hồi và tiết kiệm băng thông.
- Xử lý dữ liệu biên: các phương pháp gần đúng trong dữ liệu lớn có thể hữu ích cho các ứng dụng kiểm tra dữ liệu đến, nhật ký và các truy vấn để tạo ra kết quả tổng hợp hoặc trang tổng quan. Các ứng dụng này thời gian, công sức và tiền bạc nhất do đầu ra nhỏ hơn đáng kể so với đầu vào.
- Kết luận
Dữ liệu lớn luôn tiềm tàng các giá trị vô cùng to lớn. Hiện đã có khá nhiều nền tảng, công cụ và các kỹ thuật được đề xuất phục vụ cho việc lưu trữ, xử lý và khai thác dữ liệu lớn. Tuy nhiên, do các đặc trưng riêng của dữ liệu lớn, các công việc này đặc biệt là việc phân tích dữ liệu lớn còn gặp khá nhiều khó khăn và việc đề xuất, cải tiến các công cụ và kỹ thuật hiện có nhằm nâng cao hiệu quả khai thác dữ liệu lớn vẫn là một hướng đi mở đầy tiềm năng trong tương lai.
Tài liệu tham khảo:
- Abdalla, H. B. (2022). A brief survey on big data: technologies, terminologies and data-intensive applications. Journal of Big Data, 9(1), 1-36.
- Acharjya, D. P., & Ahmed, K. (2016). A survey on big data analytics: challenges, open research issues and tools. International Journal of Advanced Computer Science and Applications, 7(2), 511-518.
- Trần Việt Trung (2021). Bài giảng lưu trữ và xử lý dữ liệu lớn. Đại học Bách khoa Hà Nội.
Website:
[i] https://aws.amazon.com/nosql/?nc1=h_ls, https://www.mongodb.com/nosql-explained
[ii] https://cassandra.apache.org/_/cassandra-basics.html
[iii] https://aws.amazon.com/what-is/hadoop/
[iv] https://storm.apache.org/
[v] https://spark.apache.org/, https://aws.amazon.com/what-is/apache-spark/
[vi] https://www.simplilearn.com/tutorials/hadoop-tutorial/hive
Lê Thị Nhung – Khoa CNTT.