Nghiên cứu tìm hiểu các kỹ thuật xây dựng máy tìm kiếm – Search engine
Trong môi trường Internet hiện nay, lượng thông tin khổng lồ từ các trang web đang gia tăng đáng kể. Các thông tin này được lưu trữ trong nhiều dạng tài liệu khác nhau: hình ảnh, âm thanh, video, file pdf, … Tìm kiếm thông tin trở thành nhu cầu không thể thiếu, và người dùng muốn tìm kiếm không chỉ văn bản mà còn cả hình ảnh, âm thanh, video, và nhiều loại tập tin khác. Tuy nhiên, việc phát triển một công cụ tìm kiếm chính xác và nhanh chóng đang là một thách thức đối với các nhà phát triển. Điều này đòi hỏi kiến thức về thuật toán, cấu trúc dữ liệu, tổ chức cơ sở dữ liệu, và hệ thống phân tán.
Với mong muốn tìm hiểu, nghiên cứu cách hoạt động của các công cụ tìm kiếm, nghiên cứu các thuật toán của các công cụ tìm kiếm, từ đó ứng dụng xây dựng được một công cụ tìm kiếm là rất cần thiết. Nhóm sinh viên khoa CNTT đã thực hiện đề tài SVNCKH 2024 “Nghiên cứu các kỹ thuật xây dựng máy tìm kiếm– Search engine” nhằm khám phá bản chất, phương thức hoạt động của các máy tìm kiếm. Nghiên cứu các thuật toán tìm kiếm trong các Search Engine từ đó có thể ứng dụng xây dựng 1 bộ máy tìm kiếm đơn giản. Đề tài tập trung tìm hiểu về lý thuyết phân tích và nghiên cứu cấu trúc chung của một số search engine và trình bày một số kỹ thuật, thuật toán để xây dựng nên một search engine nhằm mục đích đảm bảo cho hệ thống tìm kiếm với các mô hình thông dụng hiện nay thông qua việc phân tích và cài đặt thử nghiệm thuật toán trên một máy đơn.
1. Khái niệm về Search Engine (SE)
Trong một vài thập kỷ gần đây, với sự phát triển mạnh mẽ của ngành công nghệ thông tin, Internet đã dần dần trở thành một bộ phận và là công cụ không thể thiếu được trong đời sống con người. Internet đã đi vào mọi lĩnh vực, mọi ngành từ việc tư vấn kinh doanh, sức khoẻ pháp luật đến việc mua bán hàng hoá, các vấn đề nghiên cứu khoa học chuyên sâu và cả vấn đề phát triển nhanh chóng và đa dạng hơn nhằm đáp ứng nhu cầu của con người. Các thông tin trên internet thường được viết dưới dạng các trang web và được phân tán khắp nơi trên thế giới. Các tài liệu này có những phần liên kết đến các tài liệu khác trong cùng một máy hay trên các máy khác nhau. Các trang web không được truy xuất một cách tuần tự mà thường được thiết kế để người dùng có thể truy nhập đến các mục, các trang có liên quan đến cùng một vấn đề. Để truy xuất trang web, ta thường dùng các hàm trình duyệt web. Lượng thông tin trên web tăng theo hàm mũ và các thông tin này được quản lý bởi các cá nhân, các tổ chức hoặc các công ty. Web có thể được xem như là một cơ sở dữ liệu khổng lồ không có cấu trúc chung và phân tán khắp nơi trên thế giới. Người sử dụng hầu như có thể tìm được bất kỳ thông tin gì mà họ cần trên Internet. Nhưng cũng do chính lượng thông tin khổng lồ ấy mà người sử dụng gặp phải vấn đề là thông tin mình cần nằm ở đâu ? Thông tin nào là hữu ích hơn cả? Vì vậy cần có những công cụ quản lý, tìm kiếm lọc các thông tin trên cơ sở dữ liệu khổng lồ đó. Từ đó, các SE ra đời. Hầu hết các SE đều chịu sự quản lý của các công ty và các thông tin kỹ thuật đều không được công khai nên việc nghiên cứu các SE là một điều rất khó khăn.
SE là một công cụ thực hiện việc tìm kiếm và sắp xếp thông tin giúp người dùng tìm kiếm thông tin cần thiết trên kho dữ liệu khổng lồ Internet.
Các SE phải đáp ứng được hai yêu cầu cơ bản: thông tin mà các SE tìm được phải thoả mãn yêu cầu người dùng và thời gian tìm kiếm phải ở mức có thể chấp nhận được. Người sử dụng luôn mong muốn ở các SE những thông tin cần thiết không thật rõ ràng nhưng lại yêu cầu nhận được kết quả trả về các SE là các thông tin mà mình mong muốn một cách chính xác nhanh chóng và có cấu trúc hợp lý. Do đó, các SE ngày càng phát triển hơn, càng hoàn thiện hơn để đáp ứng các yêu cầu người dùng. Các SE được đánh giá theo các tiêu chuẩn sau: Hiệu quả trong việc định vị và phân loại các tài liệu định dạng web Phạm vi tìm kiếm; Cập nhật được những thay đổi thông tin trên Internet kịp thời; Giao diện thân thiện với người dùng; Kết quả tìm kiếm có ý nghĩa và tiện dụng; Giao diện hệ thống phù hợp với người dùng truy vấn.
Khó khăn của các công cụ tìm kiếm: Lượng dữ liệu khổng lồ; Chất lượng thông tin không đồng đều; Giới hạn từ các trang web; Hiểu ngôn ngữ tự nhiên.
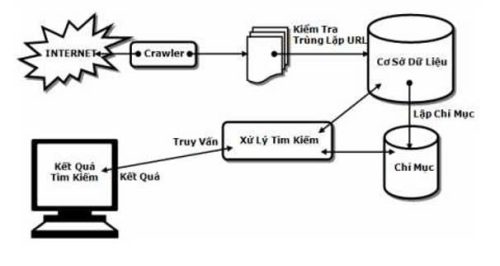
Hình 1. Cấu trúc cơ bản của một Search Engine
2. Kết quả của đề tài:
* Về mặt lý thuyết:
Từ quá trình nghiên cứu lý thuyết về Search Engine nhóm sinh viên nghiên cứu đã hiểu rõ hơn về cơ sở của các thuật toán và kỹ thuật cơ bản trong việc xây dựng một công cụ tìm kiếm hiệu quả. Cụ thể, nhóm sinh viên đã nghiên cứu các thành phần chính trong công cụ tìm kiếm và cách chúng tương tác với nhau:
- Thuật toán PageRank:
Nghiên cứu lý thuyết về thuật toán PageRank đã giúp nhóm em hiểu rõ cách thức xếp hạng các trang web dựa trên số lượng và chất lượng liên kết đến chúng. Đây là một trong những yếu tố quan trọng trong việc xác định độ tin cậy và mức độ quan trọng của các trang web trong kết quả tìm kiếm. - Quy trình thu thập dữ liệu (Web Crawling):
Tìm hiểu về các thuật toán thu thập dữ liệu như Depth-First Search (DFS) và Breadth-First Search (BFS) đã giúp nhóm em nắm được các phương pháp tối ưu để thu thập thông tin từ các trang web, giúp xây dựng cơ sở dữ liệu cho công cụ tìm kiếm. Những thuật toán này cung cấp nền tảng vững chắc cho việc tiếp cận và tổ chức dữ liệu hiệu quả. - Lập chỉ mục (Indexing):
Qua nghiên cứu lý thuyết về Inverted Index, nhóm em đã hiểu được cách thức phân tích và lập chỉ mục các từ khóa trên các trang web để tìm kiếm hiệu quả. Việc lập chỉ mục giúp tăng tốc độ truy vấn và trả kết quả tìm kiếm chính xác hơn.
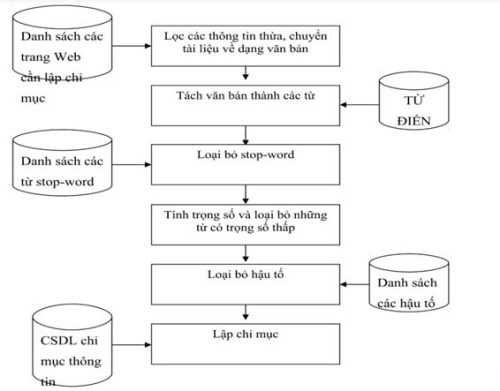
Hình 2. Lưu đồ xử lý hệ thống lập chỉ mục
- Xử lý truy vấn và xếp hạng kết quả:
Nghiên cứu lý thuyết về xử lý truy vấn giúp nhóm em hiểu được các phương pháp để phân tích và xử lý câu truy vấn của người dùng, loại bỏ các từ dừng (stop words) và cải thiện độ chính xác của kết quả trả về. Cùng với đó, nghiên cứu về PageRank và các thuật toán xếp hạng khác đã giúp nhóm em hiểu được cách thức sắp xếp kết quả tìm kiếm theo độ liên quan, từ đó cải thiện trải nghiệm người dùng. - Xử lý ngôn ngữ tự nhiên (NLP):
Qua nghiên cứu lý thuyết, nhóm em nhận ra tầm quan trọng của việc xử lý ngôn ngữ tự nhiên trong các công cụ tìm kiếm, đặc biệt là trong việc hiểu và phân tích các truy vấn phức tạp. Những kỹ thuật NLP như phân tách từ (tokenization), gắn nhãn từ loại (POS tagging) và lemmatization là rất quan trọng để cải thiện độ chính xác trong việc xử lý các câu truy vấn.
* Về mặt thực nghiệm
Nhóm sinh viên nghiên cứu đã bước đầu xây dựng được bộ máy tìm kiếm có các khả năng:
- Khả năng tìm kiếm hiệu quả: Công cụ tìm kiếm của nhóm có thể nhanh chóng thu thập và trả về các kết quả phù hợp với các truy vấn của người dùng, giúp tiết kiệm thời gian và công sức trong việc tìm kiếm thông tin.
- Tối ưu hóa kết quả: Nhờ vào việc áp dụng các thuật toán xếp hạng tiên tiến, công cụ tìm kiếm đã đảm bảo được các kết quả hiển thị là những thông tin chất lượng.
Hạn chế:
- Một số trang web có nội dung không chính xác ảnh hưởng đến hệ thống các từ khoá
- Cơ sở dữ liệu còn hạn chế
- Giao diện của search engine còn thô sơ
- Người dùng khi tìm kiếm cần phải nhập đúng chính tả câu từ cần tìm
- Chưa có hệ thống gợi ý tìm kiếm cho người dùng

Hình 3: Giao diện ban đầu của search engine: người dùng cần nhập từ khoá muốn tìm kiếm vào vùng màu trắng.
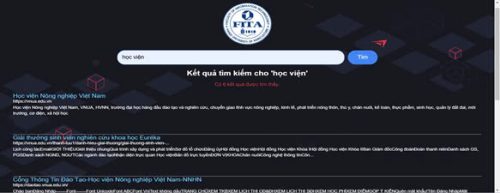
Hình 4: Giao diện của Search Engine search trả về các kết quả tìm kiếm được liên quan đến từ khoá đã nhập.
3. Hướng phát triển
- Nghiên cứu kết hợp trí tuệ nhân tạo và học máy: Việc tích hợp các thuật toán học máy, học sâu vào hệ thống sẽ giúp công cụ tìm kiếm hiểu rõ hơn về ngữ nghĩa của truy vấn, từ đó cung cấp kết quả chính xác và phù hợp hơn, đặc biệt là đối với những truy vấn phức tạp.
- Mở rộng thêm khả năng tìm kiếm bằng hình ảnh: Hệ thống sẽ phát triển khả năng nhận diện hình ảnh, giúp người dùng tìm kiếm thông tin qua hình ảnh thay vì chỉ dựa vào từ khóa, mang lại trải nghiệm tìm kiếm đa dạng hơn.
- Nghiên cứu công cụ tìm kiếm để có thể gợi ý tìm kiếm thông minh: Công cụ tìm kiếm sẽ không chỉ trả về kết quả theo yêu cầu, mà còn gợi ý các truy vấn liên quan, giúp người dùng khám phá thêm các thông tin hữu ích mà họ có thể chưa nghĩ đến.
4. Kết luận
Mô hình tìm kiếm thử nghiệm của nhóm sinh viên hiện đã hoạt động đúng như kỳ vọng ban đầu, có khả năng trả về kết quả phù hợp với các truy vấn của người dùng. Tuy nhiên, trong quá trình phát triển, vẫn còn nhiều vấn đề cần cải tiến và điều chỉnh. Đặc biệt, các thuật toán xếp hạng, thu thập dữ liệu, và xử lý truy vấn cần tiếp tục được tối ưu để nâng cao hiệu quả tìm kiếm và giảm thiểu thời gian phản hồi.
Khoa Công nghệ thông tin