Báo cáo tổng kết đề tài SVNCKH 2024: “Nghiên cứu các kỹ thuật xây dựng máy tìm kiếm – Search engine”
TÓM TẮT
Lượng thông tin trên Internet là rất lớn và được phân tán khắp nơi trên thế giới. Các thông tin này được lưu trữ trong nhiều dạng tài liệu khác nhau: hình ảnh, âm thanh, video, file pdf,… cho nên việc xây dựng các search engine cũng rất phức tạp. Các search engine thường được phát triển theo một số chỉ tiêu nhất định nào đó như chỉ tiêu về thời gian, chỉ tiêu về tìm kiếm: tìm kiếm theo toán tử boolean, tìm kiếm theo chủ đề,… Báo cáo này tập trung phân tích và nghiên cứu cấu trúc chung của một số search engine và trình bày một số kỹ thuật, thuật toán để xây dựng nên một search engine. Tuy nhiên, báo cáo này không đặt mục tiêu chính là xây dựng một search engine hoàn chỉnh mà chỉ trình bày phần lý thuyết đảm bảo cho hệ thống tìm kiếm với các mô hình thông dụng hiện nay thông qua việc phân tích và cài đặt thử nghiệm thuật toán trên một máy đơn.
Từ khóa: Công cụ tìm kiếm, Lập chỉ mục, Thu thập dữ liệu, Truy xuất thông tin
SUMMARY
The vast amount of information on the Internet is distributed globally and stored in various formats, such as images, audio, videos, and PDF files. This makes the development of search engines highly complex. Search engines are typically developed based on specific criteria, such as time efficiency and search methods (e.g., Boolean operators or topic-based search). This report focuses on analyzing and studying the general structure of some search engines and presenting several techniques and algorithms for building a search engine. However, the primary objective of this report is not to develop a complete search engine but to provide theoretical insights that support search systems using common models today, through the analysis and experimental implementation of algorithms on a single machine.
Keywords: Data Collection, Indexing, Information Retrieval, Search Engine
I. Đặt vấn đề
1. Bối cảnh
Trong môi trường Internet hiện nay, lượng thông tin khổng lồ từ các trang web đang gia tăng đáng kể. Tìm kiếm thông tin trở thành nhu cầu không thể thiếu, và người dùng muốn tìm kiếm không chỉ văn bản mà còn cả hình ảnh, âm thanh, video, và nhiều loại tập tin khác. Tuy nhiên, việc phát triển một công cụ tìm kiếm chính xác và nhanh chóng đang là một thách thức đối với các nhà phát triển. Điều này đòi hỏi kiến thức về thuật toán, cấu trúc dữ liệu, tổ chức cơ sở dữ liệu, và hệ thống phân tán.
Là sinh viên ngành CNTT, với mong muốn tìm hiểu, nghiên cứu cách hoạt động của các công cụ tìm kiếm, nghiên cứu các thuật toán của các công cụ tìm kiếm, từ đó ứng dụng xây dựng được một công cụ tìm kiếm là rất cần thiết.Vì vậy, việc nghiên cứu và phát triển đề tài “Nghiên cứu các kỹ thuật xây dựng máy tìm kiếm” là cần thiết.
2. Tổng quan về tài liệu hỗ trợ nghiên cứu
Nguồn tài liệu tham khảo: Báo cáo đề cập đến một số sách và tài liệu quan trọng đã được sử dụng để nghiên cứu và phát triển công cụ tìm kiếm như: “Introduction to Information Retrieval” của Manning et al., “Mastering Web Scraping in Python with Scrapy and BeautifulSoup” của Robert. Ngoài ra, còn có một số tài liệu khác hỗ trợ cho việc lập chỉ mục, thu thập dữ liệu, và xử lý truy vấn.
Vai trò của tài liệu: Các tài liệu này đóng vai trò nền tảng lý thuyết và phương pháp cho việc nghiên cứu các khía cạnh quan trọng của công cụ tìm kiếm, từ kỹ thuật thu thập dữ liệu (web scraping), lập chỉ mục (index), đến xử lý truy vấn và xếp hạng kết quả.
Cách sử dụng tài liệu: Tài liệu không chỉ được sử dụng để nghiên cứu lý thuyết, mà còn là cơ sở để triển khai các thuật toán và kỹ thuật trong công cụ tìm kiếm như Inverted Index, PageRank, cùng với các thư viện Python như BeautifulSoup và Selenium.
3. Mục đích nghiên cứu
Mục tiêu tổng quát: Đề tài này nhằm khám phá bản chất, phương thức hoạt động của các máy tìm kiếm. Nghiên cứu các thuật toán tìm kiếm trong các Search Engine từ đó có thể ứng dụng xây dựng 1 bộ máy tìm kiếm đơn giản.
Mục tiêu cụ thể:
Nghiên cứu các kỹ thuật của máy tìm kiếm
- Nghiên cứu Crawlers thu thập dữ liệu
- Nghiên cứu kỹ thuật đánh chỉ mục cho dữ liệu
- Nghiên cứu kỹ thuật xử lý truy vấn.
- Nghiên cứu các công cụ để xây dựng máy tìm kiếm
- Xây dựng máy tìm kiếm thử nghiệm
II. VẬT LIỆU NGHIÊN CỨU, PHƯƠNG PHÁP NGHIÊN CỨU
1. Vật liệu nghiên cứu
Thuật toán: Các thuật toán chính được sử dụng trong quá trình phát triển Search Engine bao gồm:
- PageRank: Dùng để xếp hạng các trang web dựa trên số lượng và chất lượng các liên kết đến chúng.
- Depth-First Search (DFS): Thuật toán được sử dụng để thu thập dữ liệu web (Web Crawling).
- Inverted Index: Dùng để lập chỉ mục các từ khóa và các trang web chứa chúng.
Phạm vi: Các kỹ thuật xây dựng máy tìm kiếm (Search Engine) và ứng dụng xây dựng bộ máy tìm kiếm thử nghiệm
Đối tượng: : Các thành phần tạo nên Công cụ tìm kiếm Search Engine và các thuật toán của Search Engine
2. Phương pháp nghiên cứu phát triển Search Engine
Gồm 2 phương pháp chính:
Phương pháp nghiên cứu lý thuyết:
- Nghiên cứu các tài liệu và sách xuất bản liên quan đến lĩnh vực truy xuất thông tin (Information Retrieval) như “Introduction to Information Retrieval” của Manning et al. và “Mastering Web Scraping in Python with Scrapy and BeautifulSoup.”
Phương pháp chuyên gia:
- Thu thập ý kiến từ các chuyên gia trong lĩnh vực phát triển công cụ tìm kiếm để đánh giá hiệu quả và tính khả thi của hệ thống.
Phát triển sản phẩm theo mô hình thác nước (Waterfall):
- Dựa trên quy trình phát triển hệ thống thông qua từng bước tuần tự: thu thập dữ liệu, lập chỉ mục, xử lý truy vấn và xếp hạng kết quả.
Về Các chỉ tiêu theo dõi:
Hiệu suất của Search Engine được đánh giá dựa trên các chỉ số:
- Tốc độ thu thập dữ liệu: Kiểm tra thời gian cần thiết để crawler thu thập dữ liệu từ các trang web.
- Độ chính xác của kết quả tìm kiếm: Kiểm tra mức độ liên quan của kết quả được trả về với truy vấn của người dùng.
- Hiệu quả xếp hạng: Đánh giá độ chính xác của thuật toán PageRank trong việc xếp hạng các trang web.
III. Kết quả và thảo luận
Sau thời gian thực hiện nghiên cứu đề tài khoa học nhóm chúng em đã nghiên cứu được các nội dung sau:
1. Tổng quan về Search Engine (SE)
1.1. Khái niệm về Search Engine
Trong một vài thập kỷ gần đây, với sự phát triển mạnh mẽ của ngành công nghệ thông tin, Internet đã dần dần trở thành một bộ phận và là công cụ không thể thiếu được trong đời sống con người. Internet đã đi vào mọi lĩnh vực, mọi ngành từ việc tư vấn kinh doanh, sức khoẻ pháp luật đến việc mua bán hàng hoá, các vấn đề nghiên cứu khoa học chuyên sâu và cả vấn đề phát triển nhanh chóng và đa dạng hơn nhằm đáp ứng nhu cầu của con người. Các thông tin trên internet thường được viết dưới dạng các trang web và được phân tán khắp nơi trên thế giới. Các tài liệu này có những phần liên kết đến các tài liệu khác trong cùng một máy hay trên các máy khác nhau. Các trang web không được truy xuất một cách tuần tự mà thường được thiết kế để người dùng có thể truy nhập đến các mục, các trang có liên quan đến cùng một vấn đề. Để truy xuất trang web, ta thường dùng các hàm trình duyệt web. Lượng thông tin trên web tăng theo hàm mũ và các thông tin này được quản lý bởi các cá nhân, các tổ chức hoặc các công ty. Web có thể được xem như là một cơ sở dữ liệu khổng lồ không có cấu trúc chung và phân tán khắp nơi trên thế giới. Người sử dụng hầu như có thể tìm được bất kỳ thông tin gì mà họ cần trên Internet. Nhưng cũng do chính lượng thông tin khổng lồ ấy mà người sử dụng gặp phải vấn đề là thông tin mình cần nằm ở đâu ? Thông tin nào là hữu ích hơn cả? Vì vậy cần có những công cụ quản lý, tìm kiếm lọc các thông tin trên cơ sở dữ liệu khổng lồ đó. Từ đó, các SE ra đời. Hầu hết các SE đều chịu sự quản lý của các công ty và các thông tin kỹ thuật đều không được công khai nên việc nghiên cứu các SE là một điều rất khó khăn.
SE là một công cụ thực hiện việc tìm kiếm và sắp xếp thông tin giúp người dùng tìm kiếm thông tin cần thiết trên kho dữ liệu khổng lồ Internet.
Các SE phải đáp ứng được hai yêu cầu cơ bản: thông tin mà các SE tìm được phải thoả mãn yêu cầu người dùng và thời gian tìm kiếm phải ở mức có thể chấp nhận được. Người sử dụng luôn mong muốn ở các SE những thông tin cần thiết không thật rõ ràng nhưng lại yêu cầu nhận được kết quả trả về các SE là các thông tin mà mình mong muốn một cách chính xác nhanh chóng và có cấu trúc hợp lý. Do đó, các SE ngày càng phát triển hơn, càng hoàn thiện hơn để đáp ứng các yêu cầu người dùng. Các SE được đánh giá theo các tiêu chuẩn sau:
- Hiệu quả trong việc định vị và phân loại các tài liệu định dạng web Phạm vi tìm kiếm
- Cập nhật được những thay đổi thông tin trên Internet kịp thời
- Giao diện thân thiện với người dùng
- Kết quả tìm kiếm có ý nghĩa và tiện dụng
- Giao diện hệ thống phù hợp với người dùng truy vấn
Khó khăn của các công cụ tìm kiếm:
- Lượng dữ liệu khổng lồ: Với sự gia tăng nhanh chóng của dữ liệu trên internet, việc xử lý và tìm kiếm thông tin hiệu quả trong một kho dữ liệu khổng lồ vẫn là một thách thức lớn đối với hệ thống.
- Chất lượng thông tin không đồng đều: Nhiều trang web có nội dung không chính xác hoặc không liên quan đến nhu cầu tìm kiếm của người dùng, tạo ra khó khăn trong việc đảm bảo tính chính xác và độ tin cậy của kết quả tìm kiếm.
- Giới hạn từ các trang web: Một số trang web không cho phép việc thu thập dữ liệu (cào dữ liệu), điều này làm giảm khả năng truy cập và xử lý thông tin từ các nguồn phong phú.
- Hiểu ngôn ngữ tự nhiên: Sự phức tạp và đa dạng trong ngôn ngữ tự nhiên, đặc biệt là các sắc thái ngữ nghĩa, khiến cho việc hiểu và xử lý các truy vấn trở thành một thách thức lớn đối với hệ thống tìm kiếm.
1.2. Cấu trúc cơ bản của một SE
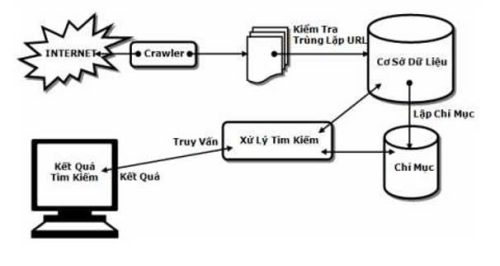
Hình 1. Cấu trúc cơ bản của một Search Engine
Crawler (Spider): là thành phần chịu trách nhiệm thu thập dữ liệu từ Internet. Các chức năng của nó bao gồm:
- Gửi yêu cầu HTTP đến máy chủ web
- Trích xuất dữ liệu HTML và liên kết đến các trang web khác
- Lưu trữ dữ liệu thu thập được trong cơ sở dữ liệu
Crawler sử dụng các thuật toán như Breadth-First Search (BFS) và Depth-First Search (DFS) để điều hướng web. Nó cũng sử dụng các thư viện như Requests và BeautifulSoup để gửi yêu cầu HTTP và phân tích dữ liệu HTML.
Indexer: là thành phần chịu trách nhiệm xử lý và lưu trữ dữ liệu thu thập được. Các chức năng của nó bao gồm:
- Xử lý dữ liệu thu thập được
- Tạo chỉ mục của các từ khóa và trang web chứa chúng
- Lưu trữ chỉ mục trong cơ sở dữ liệu
Indexer sử dụng các thuật toán như Inverted Index để tạo chỉ mục. Nó cũng sử dụng các thư viện như pandas để lưu trữ và thao tác dữ liệu.
Retriever (Query): là thành phần chịu trách nhiệm trả về kết quả tìm kiếm cho người dùng. Các chức năng của nó bao gồm:
- Sử dụng chỉ mục được tạo bởi Indexer để tìm kiếm trang web phù hợp với truy vấn của người dùng
- Trả về kết quả tìm kiếm cho người dùng
Retriever sử dụng các thuật toán như Boolean Retrieval và Vector Space Model để tìm kiếm trang web liên quan. Nó cũng sử dụng các thư viện như numpy để thực hiện các phép toán vectơ.
Thuật toán xếp hạng: là thành phần chịu trách nhiệm xếp hạng trang web dựa trên độ liên quan của chúng với truy vấn của người dùng. Các chức năng của nó bao gồm:
- Xếp hạng trang web dựa trên độ liên quan của chúng với truy vấn của người dùng
- Trả về kết quả tìm kiếm được xếp hạng cho người dùng
PageRank là một thuật toán xếp hạng nổi tiếng của Google, nó là sự khác biệt hoàn toàn khiến cho Google trở thành một trong những công cụ tìm kiếm hàng đầu.
2. Một số kỹ thuật cơ bản của Search Engine
2.1. Thu thập dữ liệu (Web Crawling)
Quá trình thu thập dữ liệu từ các trang web được gọi là Web Crawling. Quy trình này bắt đầu từ một URL cụ thể, sau đó crawler (bot tự động) sẽ theo dõi các liên kết trên trang web để lần lượt thu thập thông tin một cách hệ thống. Mục tiêu là xây dựng một kho lưu trữ dữ liệu lớn chứa các trang web, bài viết, hoặc nội dung liên quan đến truy vấn của người dùng.
Trong Python, việc trích xuất dữ liệu từ web được hỗ trợ bởi các thư viện mạnh mẽ như Requests, BeautifulSoup, giúp phân tích và xử lý dữ liệu từ các trang web một cách hiệu quả.
Thuật toán tìm kiếm theo chiều sâu (DFS):
Sau đây các quy trình thực hiện thu nhập dữ liệu bằng phương pháp tìm kiếm sâu mà nhóm nhóm em đã thực hiện:
Bước 1: Tạo mảng danh sách chứa URL đã truy cập hay ở đây nhóm em gọi là tập visited, to_visit: Ngăn xếp (stack) để lưu các URL chờ được duyệt, hỗ trợ duyệt theo chiều sâu.
Bước 2: Tiến hành lấy URL. Tại điểm này, chương trình kiểm tra điều kiện để chuyển sang bước tiếp theo. URL được lấy từ cuối ngăn xếp theo phương pháp (DFS)
Danh sách visited ở đây sẽ kiểm tra trùng lặp qua mảng danh sách lưu trữ to_visit
- Nếu đã kiểm tra, quay lại bước 2 để xử lý trang tiếp theo.
- Nếu chưa kiểm tra, chuyển sang bước 3.
Bước 3: Đánh dấu trang hiện tại là đã được xét. Sau đó, chương trình phân tích và tìm kiếm liên kết trong trang.
- Nếu tìm thấy liên kết, thêm liên kết đó vào đầu danh sách và quay lại bước 3.
- Nếu không có liên kết, quay lại bước 2.
Bước 4: Quy trình kết thúc. Tiến hành phương pháp tìm kiếm theo chiều sâu này giúp tối ưu việc thu nhập dữ liệu đảm bảo khả năng kiểm tra cũng như thu nhập URL một cách hệ thống nhất.
2.2. Quy trình lập chỉ mục (Indexing)
Lập chỉ mục được tiến hành sau khi đã thu nhập được dữ liệu từ phương pháp cào DFS. Việc tiến hành lập chỉ mục cho Search Engine nhằm giúp truy xuất thông tin nhanh chóng khi người dùng tiến hành truy vấn. Cụ thể, các tài liệu chủ yếu là trang web, sẽ được phân tích và trích xuất từ khóa nhằm mục đích tạo chỉ mục giúp tăng tốc độ tìm kiếm các tài liệu chứa từ khóa tương ứng.
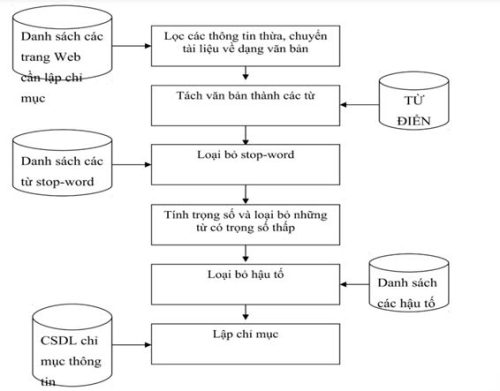
Hình 2. Lưu đồ xử lý hệ thống lập chỉ mục
Lập chỉ mục là quá trình phân tích và xác định các từ, cụm từ phù hợp có thể mô tả nội dung của tài liệu. Do đó, vấn đề đặt ra là phải rút ra những thông tin quan trọng và có thể được sử dụng như một phần của nội dung tài liệu. Để giảm chi phí lưu trữ và tìm kiếm và loại bỏ kết quả dư thừa, thông tin này phải “vừa đủ”, nghĩa là không thể thiếu để cung cấp kết quả đầy đủ so với nhu cầu tìm kiếm.
Phương pháp lập chỉ mục gồm 2 phần chính yếu sau:
- Đầu tiên, xác định các ý tưởng và mục tiêu có thể được lưu trữ trong văn bản. Điều này bao gồm việc loại bỏ các stop-word, tách từ và xử lý văn bản, hậu tố…)
- Ví dụ tách từ: “Đào tạo Học Viện Nông Nghiệp Việt Nam” được tách thành “Đào tạo”,”học”,”viện”,”Nông Nghiệp”,”Việt Nam”
- Ví dụ loại bỏ stop-word: Loại bỏ những từ không mang nhiều ý nghĩa trong ngữ cảnh tìm kiếm (như “và”, “là”, “theo” hay là a, an, the trong tiếng anh). Những từ này thường không cần thiết cho việc tìm kiếm và một số khác như xử lí hậu tố,..
- Thứ hai là xác định trọng số cho từng mục từ; giá trị này thể hiện tầm quan trọng của mỗi mục từ trong ngữ cảnh.
- Phương pháp lập chỉ mục tiếng anh gồm:
- Tách từ: Việc phân biệt từ trong câu dựa trên khoảng trắng giúp xác định các mục từ chính xác.
- Loại bỏ stop-words: Các từ không mang ý nghĩa lớn (stop-words) cần được loại bỏ vì chúng thường chiếm phần lớn trong văn bản, làm giảm độ chính xác của chỉ mục.
- Hệ thống đánh chỉ mục toàn văn bản: Áp dụng các hệ thống chỉ mục cho toàn bộ văn bản để đánh giá tần suất xuất hiện và xác định các mục từ quan trọng.
- Sử dụng từ điển: Kiểm tra và so sánh từ cần phân tích với từ điển để tăng độ chính xác trong việc lập chỉ mục.
- Phương pháp lập chỉ mục cho tài liệu tiếng Việt bao gồm:
- Chính tả và viết hoa: Cần xử lý các vấn đề liên quan đến chính tả và viết hoa, như sự không thống nhất giữa việc sử dụng “y” hay “i”, và cách viết hoa tên riêng.
- Loại bỏ stop-words: Các từ không mang nhiều ý nghĩa thường chiếm tỷ lệ lớn trong văn bản. Việc loại bỏ chúng là cần thiết để tăng độ chính xác của chỉ mục.
- Từ đa nghĩa: Tính phong phú về nghĩa của từ (từ đa nghĩa) cần được xử lý phù hợp để tránh nhầm lẫn khi tìm kiếm.
- Bảng mã tiếng Việt: Xử lý các bảng mã khác nhau để đảm bảo tính nhất quán trong việc lập chỉ mục tài liệu.
- Khó khăn cho việc lập chỉ mục tiếng Việt:
- Phân tách từ: Tiếng Việt không sử dụng khoảng trắng để phân biệt từ một cách rõ ràng như tiếng Anh. Việc xác định ranh giới giữa các từ gặp khó khăn do có thể có nhiều cách ghép từ.
- Đa nghĩa và đồng nghĩa: Nhiều từ tiếng Việt có thể có nhiều nghĩa khác nhau hoặc đồng nghĩa với các từ khác, gây khó khăn trong việc xác định ngữ cảnh và nội dung chính xác.
- Stop-words: Số lượng từ không mang ý nghĩa lớn (stop-words) rất cao trong tiếng Việt, và việc xác định và loại bỏ chúng có thể gặp khó khăn.
- Ngữ pháp phức tạp: Cấu trúc ngữ pháp phong phú và đa dạng cũng khiến cho việc lập chỉ mục chính xác trở nên khó khăn hơn.
- Chính tả và viết hoa: Các vấn đề về chính tả, cú pháp, và quy tắc viết hoa có thể ảnh hưởng đến khả năng tìm kiếm và lập chỉ mục.
- Bảng mã và ký tự đặc biệt: Quản lý và xử lý các bảng mã ký tự khác nhau có thể gây ra vấn đề trong việc lập chỉ mục và tìm kiếm hiệu quả.
2.3. Quy trình xử lý truy vấn (Queries)
Truy vấn tìm kiếm (Search Query Processing)
- Xử lý truy vấn bằng cách sử dụng từ khóa. Hầu hết các công cụ tìm kiếm sử dụng phương pháp này. Ngược lại, các từ khóa tài liệu trên trang web được sử dụng vào tìm kiếm. Do đó, các công cụ tìm kiếm sẽ tự động chọn và đánh chỉ mục các từ quan trọng để giúp phân biệt các tài liệu. Công cụ tìm kiếm sẽ tìm kiếm trong cơ sở dữ liệu đã được thiết lập chỉ sau khi nhận được truy vấn và cung cấp các kết quả phù hợp.
- Search engine thường gặp rắc rối với những từ đồng âm khác (ví dụ: strong cider, strong stone, a tough exam, hard disk) hoặc những từ có các biến thể khác nhau do có tiền tố và hậu tố như large, larger, learner, learners, … Bên cạnh đó search engine cũng không thể trả về các tài liệu chứa những từ đồng nghĩa với các từ trong truy vấn.
- Xử lý truy vấn bằng tìm kiếm dựa trên ý nghĩa:
- Tìm kiếm dựa trên ý nghĩa là một phương pháp giúp người dùng truy cập xuất thông tin bằng cách hiểu các mối quan hệ và ý nghĩa của các từ và khái niệm của chúng thay vì chỉ tìm kiếm các từ trong tài liệu qua keyword. Bằng cách dựa trên ý nghĩa tìm kiếm sẽ xem xét mối liên hệ giữa các thuật ngữ, không giống như phương pháp tìm kiếm từ khóa (keyword).
- Phương pháp này không chỉ đơn thuần là xác định những từ khóa quan trọng mà còn phân tích tần suất xuất hiện trong tài liệu. Vì thế dễ dàng phân nhóm tài liệu có liên quan để đề xuất cho người dùng.
2.4. Xếp hạng kết quả (Ranking Results)
Search Engine sẽ xếp hạng các tài liệu theo cấp độ liên quan đến các câu hỏi của người dùng sau khi tìm thấy liên kết tài liệu. Kết quả xếp hạng là bước quan trọng để đảm bảo rằng tài liệu có liên quan nhất, được xem nhiều nhất sẽ xuất hiện ở kết quả đầu trang.
Thuật toán PageRank để xếp hạng PageRank
- Khái niệm cơ bản: PageRank coi mỗi liên kết giữa các trang là một “biểu quyết”. Một trang càng nhận được nhiều “biểu quyết” từ các trang khác có độ tin cậy cao thì rank của nó càng cao. Cho nên không chỉ số lượng liên kết quan trọng, mà còn là chất lượng của những liên kết đó.
- Thuật toán PageRank đánh giá mức độ quan trọng của một trang web dựa trên số lượng và chất lượng các liên kết trỏ đến nó. Công thức chính:
- d là hệ số giảm dần (thường 0.85), N là tổng số trang, Pi là các trang trỏ đến P, và L(Pi) là số liên kết từ Pi.
- Trang được xếp hạng cao nếu có nhiều liên kết từ các trang mang độ tin cậy cao.
PageRank lặp lại tính toán cho đến khi ổn định, xếp hạng trang theo mức độ quan trọng.
Ý tưởng hoạt động của thuật toán:
- Theo như ý tưởng thì một trang web được coi là đáng tin cậy, có độ tin cậy cao khi và chỉ khi được nhiều trang khác “tin cậy” trỏ đến
- Các yếu tố chính hình thành thuật toán gồm:
+ Số lượng liên kết trỏ đến trang giả sử trang A cùng trỏ đến B và C thì sẽ chia đều độ tin cậy cho cả 2 trang
+ Về chất lượng liên kết khi và chỉ khi một trang được xếp hạng cao có liên kết đến các trang còn lại thì xếp hạng của các trang đó cũng cao hơn
+ Hệ số giảm: Được thêm vào để giả định rằng người dùng không nhấp vào các liên kết mà vẫn có thể chọn ngẫu nhiên một trang bất kỳ trên web để truy cập. Điều này giúp thuật toán tránh bị kẹt và tiếp tục tính toán đúng kể cả trường hợp những trang không có liên kết ngoài.
Ưu điểm:
- Giúp xác định trang có chứa nguồn đáng tin cậy.
- Cung cấp phương pháp để đánh giá chất lượng thông tin trên internet.
Hạn chế:
- Không phải tất cả các yếu tố xếp hạng đều được thể hiện qua PageRank, vì nó chủ yếu tập trung vào liên kết bên ngoài.
Ngoài ra còn các tiêu chí khác để xếp hạng một website như là:
- Chất lượng nội dung
- Backlinks
- Tốc độ tải trang
- Uy tín của tên miền (Lịch sử hoạt động)
Ở đây nhóm nghiên cứu sử dụng tuổi miền và tốc độ tải trang làm phương pháp chính để xếp hạng kết quả:
- Tuổi miền: Tuổi miền đề cập đến khoảng thời gian mà một miền đã được đăng ký.
- Tốc độ tải trang: Tốc độ tải trang ảnh hưởng trực tiếp đến trải nghiệm người dùng, trang tải nhanh sẽ được ưu tiên đánh giá cao hơn, trong khi trang tải chậm sẽ bị đánh giá thấp. Giá trị càng nhỏ (tải càng nhanh) rank càng cao.
Ưu điểm:
- Đơn giản và hiệu quả:
Sử dụng tuổi tên miền và tốc độ tải trang làm tiêu chí đánh giá xếp hạng mà không cần xử lý quá nhiều yếu tố phức tạp về nội dung cũng như liên kết (backlinks).
+ Tuổi tên miền: phản ánh độ tin cậy lâu dài của website.
+ Tốc độ tải trang: đảm bảo trải nghiệm người dùng tốt hơn, yếu tố quan trọng trong xếp hạng.
- Thực tế và dễ triển khai:
Tuổi tên miền và tốc độ tải trang đều có thể đo lường một cách chính xác để thu nhập dữ liệu dễ dàng với các công cụ như WHOIS (cho tuổi miền) hoặc Lighthouse/Google PageSpeed Insights (cho tốc độ tải trang).
Hạn chế:
- Các trang web có cùng tên miền sẽ gần như có xếp hạng ngang nhau
- Bỏ qua nhiều yếu tố quan trọng:
- Chất lượng nội dung (phù hợp với nhu cầu người dùng).
- Backlinks (liên kết từ các trang uy tín).
- Trải nghiệm người dùng (UX) như tính tương thích di động hoặc thiết kế giao diện. Đều đóng vai trò lớn trong xếp hạng của công cụ tìm kiếm thực tế.
3. Thiết kế và viết chương trình
3.1. Thiết kế
Hệ thống Search Engine bao gồm các thành phần chính sau đây:
Crawler (Bộ thu thập dữ liệu):
- Trích xuất nội dung từ các trang web mục tiêu.
- Lọc và xử lý dữ liệu trước khi lưu vào cơ sở dữ liệu.
- Kiểm tra các quy tắc trong robots.txt để đảm bảo crawl dữ liệu hợp pháp.
Indexer (Bộ lập chỉ mục):
- Lưu trữ dữ liệu vào cơ sở dữ liệu MySQL.
- Chuyển đổi và chuẩn hóa dữ liệu, tạo từ khóa để hỗ trợ quá trình tìm kiếm.
Retriever (Bộ truy vấn):
- Xử lý truy vấn, tìm kiếm bằng từ khoá
- Trả về các url tương ứng được tìm thấy trong cơ sở dữ liệu
Ranking (Bộ xếp hạng):
- Tính toán độ ưu tiên cho các kết quả tìm kiếm dựa trên tuổi của tên miền và tốc độ tải trang.
3.2. Lập trình
Ngôn ngữ lập trình:
Nhóm nghiên cứu sử dụng Python làm ngôn ngữ lập trình chính để xây dựng Search Engine. Python được chọn vì khả năng hỗ trợ mạnh mẽ trong xử lý dữ liệu, phát triển nhanh chóng, và có một hệ sinh thái thư viện phong phú dành cho lập trình web, xử lý ngôn ngữ tự nhiên, và thao tác cơ sở dữ liệu.
Môi trường lập trình:
- IDE (Integrated Development Environment): Visual Studio Code với các tiện ích hỗ trợ như Python Extension Pack, Pylint.
- Phiên bản Python: Python 3.10 (hoặc phiên bản tương đương trở lên).
- Hệ điều hành: Windows 10.
- Cơ sở dữ liệu: MySQL (truy cập qua XAMPP).
Các module và thư viện đã cài đặt:
Dưới đây là danh sách các module và thư viện chính đã được cài đặt và sử dụng trong chương trình:
- requests: Dùng để gửi các yêu cầu HTTP và tải nội dung từ các trang web.
- BeautifulSoup (thuộc thư viện bs4): Hỗ trợ phân tích cú pháp HTML và trích xuất thông tin từ các thẻ HTML.
- mysql-connector-python: Kết nối Python với cơ sở dữ liệu MySQL để lưu trữ dữ liệu.
- pyvi: Xử lý ngôn ngữ tự nhiên tiếng Việt, bao gồm tách từ và gắn thẻ từ loại.
- langid: Dùng để nhận diện ngôn ngữ của văn bản (tiếng Việt hoặc tiếng Anh).
- nltk: Hỗ trợ xử lý ngôn ngữ tự nhiên tiếng Anh, bao gồm các chức năng:
- Loại bỏ stopwords (từ không mang nghĩa quan trọng).
- Lemmatization (chuyển đổi từ về dạng gốc).
- POS tagging (gắn thẻ từ loại).
Các thành phần của NLTK được sử dụng trong chương trình: - stopwords
- WordNetLemmatizer
- wordnet
- averaged_perceptron_tagger_eng
- time: Để quản lý các khoảng nghỉ giữa các yêu cầu, giảm tải cho máy chủ.
- re: Xử lý và tìm kiếm mẫu chuỗi bằng biểu thức chính quy.
- parse: Để chuẩn hóa và xử lý các URL.
- robotparser: Hỗ trợ kiểm tra quyền crawl dữ liệu qua tệp robots.txt.
IV. Kết luận
1. Về mặt lý thuyết
Sau quá trình nghiên cứu lý thuyết về Search Engine đã giúp nhóm em hiểu rõ hơn về cơ sở của các thuật toán và kỹ thuật cơ bản trong việc xây dựng một công cụ tìm kiếm hiệu quả. Cụ thể, nhóm em đã nghiên cứu các thành phần chính trong công cụ tìm kiếm và cách chúng tương tác với nhau:
- Thuật toán PageRank:
Nghiên cứu lý thuyết về thuật toán PageRank đã giúp nhóm em hiểu rõ cách thức xếp hạng các trang web dựa trên số lượng và chất lượng liên kết đến chúng. Đây là một trong những yếu tố quan trọng trong việc xác định độ tin cậy và mức độ quan trọng của các trang web trong kết quả tìm kiếm. - Quy trình thu thập dữ liệu (Web Crawling):
Tìm hiểu về các thuật toán thu thập dữ liệu như Depth-First Search (DFS) và Breadth-First Search (BFS) đã giúp nhóm em nắm được các phương pháp tối ưu để thu thập thông tin từ các trang web, giúp xây dựng cơ sở dữ liệu cho công cụ tìm kiếm. Những thuật toán này cung cấp nền tảng vững chắc cho việc tiếp cận và tổ chức dữ liệu hiệu quả. - Lập chỉ mục (Indexing):
Qua nghiên cứu lý thuyết về Inverted Index, nhóm em đã hiểu được cách thức phân tích và lập chỉ mục các từ khóa trên các trang web để tìm kiếm hiệu quả. Việc lập chỉ mục giúp tăng tốc độ truy vấn và trả kết quả tìm kiếm chính xác hơn. - Xử lý truy vấn và xếp hạng kết quả:
Nghiên cứu lý thuyết về xử lý truy vấn giúp nhóm em hiểu được các phương pháp để phân tích và xử lý câu truy vấn của người dùng, loại bỏ các từ dừng (stop words) và cải thiện độ chính xác của kết quả trả về. Cùng với đó, nghiên cứu về PageRank và các thuật toán xếp hạng khác đã giúp nhóm em hiểu được cách thức sắp xếp kết quả tìm kiếm theo độ liên quan, từ đó cải thiện trải nghiệm người dùng. - Xử lý ngôn ngữ tự nhiên (NLP):
Qua nghiên cứu lý thuyết, nhóm em nhận ra tầm quan trọng của việc xử lý ngôn ngữ tự nhiên trong các công cụ tìm kiếm, đặc biệt là trong việc hiểu và phân tích các truy vấn phức tạp. Những kỹ thuật NLP như phân tách từ (tokenization), gắn nhãn từ loại (POS tagging) và lemmatization là rất quan trọng để cải thiện độ chính xác trong việc xử lý các câu truy vấn.
2. Về mặt thực nghiệm
Nhóm em đã bước đầu xây dựng được bộ máy tìm kiếm có các khả năng
- Khả năng tìm kiếm hiệu quả: Công cụ tìm kiếm của nhóm em có thể nhanh chóng thu thập và trả về các kết quả phù hợp với các truy vấn của người dùng, giúp tiết kiệm thời gian và công sức trong việc tìm kiếm thông tin.
- Tối ưu hóa kết quả: Nhờ vào việc áp dụng các thuật toán xếp hạng tiên tiến, công cụ tìm kiếm đã đảm bảo được các kết quả hiển thị là những thông tin chất lượng.
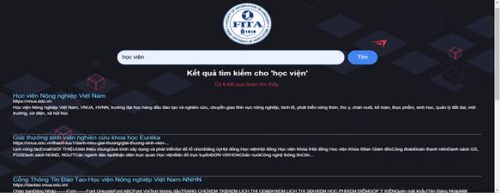
Hình 3. Giao diện của Search Engine
Hạn chế:
- Một số trang web có nội dung không chính xác ảnh hưởng đến hệ thống các từ khoá
- Cơ sở dữ liệu còn hạn chế
- Giao diện của search engine còn thô sơ
- Người dùng khi tìm kiếm cần phải nhập đúng chính tả câu từ cần tìm
- Chưa có hệ thống gợi ý tìm kiếm cho người dùng.
3. Hướng phát triển
- Nghiên cứu kết hợp trí tuệ nhân tạo và học máy: Việc tích hợp các thuật toán học máy, học sâu vào hệ thống sẽ giúp công cụ tìm kiếm hiểu rõ hơn về ngữ nghĩa của truy vấn, từ đó cung cấp kết quả chính xác và phù hợp hơn, đặc biệt là đối với những truy vấn phức tạp.
- Mở rộng thêm khả năng tìm kiếm bằng hình ảnh: Hệ thống sẽ phát triển khả năng nhận diện hình ảnh, giúp người dùng tìm kiếm thông tin qua hình ảnh thay vì chỉ dựa vào từ khóa, mang lại trải nghiệm tìm kiếm đa dạng hơn.
- Nghiên cứu công cụ tìm kiếm để có thể gợi ý tìm kiếm thông minh: Công cụ tìm kiếm sẽ không chỉ trả về kết quả theo yêu cầu, mà còn gợi ý các truy vấn liên quan, giúp người dùng khám phá thêm các thông tin hữu ích mà họ có thể chưa nghĩ đến.
4. Kết luận và đề nghị
Mô hình tìm kiếm thử nghiệm của nhóm em hiện đã hoạt động đúng như kỳ vọng ban đầu, có khả năng trả về kết quả phù hợp với các truy vấn của người dùng. Tuy nhiên, trong quá trình phát triển, vẫn còn nhiều vấn đề cần cải tiến và điều chỉnh. Đặc biệt, các thuật toán xếp hạng, thu thập dữ liệu, và xử lý truy vấn cần tiếp tục được tối ưu để nâng cao hiệu quả tìm kiếm và giảm thiểu thời gian phản hồi.
-
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.
- Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge University Press.
- The BeautifulSoup Documentation Available at: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- https://www.geeksforgeeks.org/implementing-web-scraping-python-beautiful-soup.
- The PageRank Citation Ranking: Bringing Order to the Web
- What-is-more-important-for-improving-a-sites-search-rankings-and-traffic-through-SE-page-rank-or-domain-age
Tạ Việt Đức (K66TTNTA), Nguyễn Tùng Dương(K66TTNTA), Dương Văn Duy (K65TTNTA).