Giới thiệu tổng quan về Học máy
Ngày nay, các thuật ngữ của cách mạng công nghiệp 4.0 như Robot thông minh, Trí tuệ nhân tạo đã trở lên phổ biến và quen thuộc đối với tất cả mọi người. Nhờ vào các công nghệ này, máy tính đã có thể thực hiện được những nhiệm vụ phức tạp một cách thông minh như con người.
thay vì thực hiện từng bước cụ thể được chỉ ra bởi con người để giải quyết một vấn đề thì máy tính giờ đây có thể học được thông qua việc quan sát từ dữ liệu. Bài viết này giới thiệu tổng quan về Học máy, một lĩnh vực quan trọng cốt lõi của Trí tuệ nhân tạo.
- Học máy là gì
Theo Wikipedia, Học máy (machine learning) là một lĩnh vực của trí tuệ nhân tạo liên quan đến việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống “học” tự động từ dữ liệu để giải quyết những vấn đề cụ thể. Một cách tổng quát, trong cuốn sách Machine Learning của tác giả Tom Mitchell xuất bản năm 1997, học máy được định nghĩa như sau: “A computer program is said to learn to perform a task T from experience E, if its performance at task T, as measured by a performance metric P, improves with experience E over time” (một chương trình máy tính được cho là học để thực hiện một nhiệm vụ T từ kinh nghiệm E, nếu hiệu suất thực hiện công việc T của nó được đo bởi chỉ số hiệu suất P và được cải thiện bởi kinh nghiệm E theo thời gian).
Như vậy, học máy nói đến một chương trình giúp cho máy tính có thể giải một bài toán cụ thể bằng những “kinh nghiệm” mà nó đã được “học” từ dữ liệu. Chương trình này có sự khác biệt lớn so với các chương trình lập trình truyền thống như. Sự khác biệt này có thể được mô tả trực quan như trong hình 1. Ở các chương trình lập trình truyền thống, con người sẽ phải viết ra các qui tắc, điều kiện để máy tính thực hiện nhiệm vụ và đưa ra câu trả lời. Ngược lại, đối với Học máy, nhiệm vụ của máy tính là phải dựa vào dữ liệu quan sát để tìm ra được các qui tắc này.


Tương tự như con người, máy tính cũng tự cải thiện khả năng giải quyết vấn đề thông qua việc học. Điểm khác biệt là ở chỗ, con người học được từ những quan sát thực tế, những điều mà con người được nhìn, được nghe, còn máy tính học từ dữ liệu.
- Phân loại các thuật toán học máy
Dựa trên các tiêu chí khác nhau, người ta có thể phân loại các thuật toán Học máy theo nhiều cách khác nhau. Chẳng hạn, dựa vào vấn đề, nhiệm vụ cần giải quyết của thuật toán, người ta phân loại các thuật toán Học máy thành ba loại:
- Hồi quy (Regression): Giải quyết bài toán dự đoán giá trị một đại lượng nào đó dựa vào giá trị của các đại lượng liên quan. Ví dụ, dựa vào các đặc điểm như diện tích, số phòng, khoảng cách tới trung tâm…để dự đoán giá trị căn nhà.
- Phân lớp (Classification): Giải quyết các bài toán nhận dạng xem một đối tượng thuộc lớp nào trong số các lớp cho trước. Ví dụ, bài toán nhận diện chữ viết, bài toán phân loại email…thuộc các thuật toán phân lớp.
- Phân cụm (Clustering): Ý tưởng cơ bản giống với các thuật toán phân lớp, sự khác biệt là ở chỗ, trong các bài toán phân cụm, các cụm chưa được xác định trước và thuật toán phải tự khám phá và phân cụm dữ liệu.
Dựa trên cách máy tính học, người ta chia các thuật toán Học máy thành:
- Học có giám sát (Supervised learning): Thuật toán sẽ học trên dữ liệu đã được dán nhãn. Ví dụ, trong bài toán nhận diện hình ảnh, dữ liệu đầu vào sẽ là rất nhiều bức ảnh khác nhau về loài mèo. Thuật toán sẽ học các đặc điểm quan trọng từ các bức ảnh đó để nhận biết xem một đối tượng trong một bức ảnh có phải là mèo hay không.
- Học không giám sát (Unsupervised learning): Thuật toán học trên các dữ liệu chưa được gán nhãn và sẽ phải tự khám phá ra cấu trúc, phân bố của dữ liệu để tự phân cụm chúng.
- Học bán giám sát (Semi-supervised learning): Kết hợp cả học giám sát và học không giám sát. Tức là, một số dữ liệu đầu vào sẽ được gán nhãn và một số khác thì không được gán nhãn.
- Học tăng cường/củng cố (Reinforced learning): Thuật toán sẽ tự học dựa trên việc tính điểm thưởng, phạt cho các kết quả thực hiện nhiệm vụ. Cụ thể hơn, các thuật toán học tăng cường nghiên cứu cách thức một tác nhân (Agent) trong một môi trường (Environment) đang ở một trạng thái (State) thực hiện một hành động (Action) để tối ưu hóa một phần thưởng (Reward) chung. Các chương trình máy tính như AlphaGo đã giúp máy tính đánh bại con người trong các trò chơi như cờ vua, cờ vây được xây dựng dựa trên thuật toán này.
Cần lưu ý là việc phân loại trên chỉ có tính chất tương đối vì cùng một thuật toán nhưng có thể phân loại thuộc các loại khác nhau.
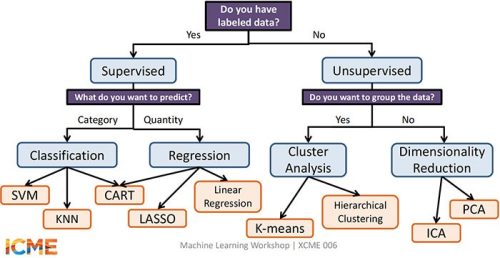
Hình vẽ 2 mô tả một cách để phân loại và lựa chọn thuật toán cho phù hợp với bài toán quan tâm.
- Các bước cơ bản thực hiện một thuật toán Học máy
Nhìn chung, việc thực hiện một thuật toán Học máy thường trải qua các bước cơ bản sau:
- Thu thập dữ liệu – Gathering data/Data collection
- Tiền xử lý dữ liệu – Data preprocessing
- Trích xuất dữ liệu – data extraction
- Làm sạch dữ liệu – data cleaning
- Chuyển đổi dữ liệu – Data transformation
- Chuẩn hóa dữ liệu – Data normalization
- Trích xuất đặc trưng – Feature extraction
- Phân tích dữ liệu – Data analysis
- Xây dựng mô hình máy học – Model building
- Huấn luyện mô hình – Model training
- Đánh giá mô hình – Model evaluation
Trong tất cả các bước thì việc thu thập dữ liệu, tiền xử lý và xây dựng bộ dữ liệu là tốn nhiều thời gian và công sức nhất. Đây là bước quan trọng, có ảnh hưởng rất nhiều đến hiệu quả của thuật toán Học máy.
Ứng dụng của Học máy
Các thuật toán Học máy đang được áp dụng rộng rãi trong rất nhiều lĩnh vực trong đời sống xã hội, từ sản xuất công nghiệp, nông nghiệp, tới tài chính, ngân hàng, y tế, giáo dục, dịch vụ giải trí… Một số ứng dụng phổ biến của Học máy có thể đề cập đến như:
a. Xử lý ảnh
Bài toán xử lý ảnh(Image Processing) giải quyết các vấn đề phân tích thông tin từ hình ảnh hay thực hiện một số phép biến đổi. Một số ví dụ là:
- Gắn thẻ hình ảnh(Image Tagging), giống như Facebook, một thuật toán tự động phát hiện khuôn mặt của bạn và bạn bè trên những bức ảnh. Về cơ bản, thuật toán này học từ những bức ảnh mà bạn tự gắn thẻ cho mình trước đó.
- Nhận dạng ký tự(Optical Character Recognition), là một thuật toán chuyển dữ liệu trên giấy tờ, văn bản thành dữ liệu số hóa. Thuật toán phải học cách nhận biết ảnh chụp của một ký tự là ký tự nào.
- Ô tô tự lái(Self-driving cars), một phần cơ chế sử dụng ở đây là xử lý ảnh. Một thuật toán machine learning giúp phát hiện các mép đường, biển báo hay các chướng ngại vật bằng cách xem xét từng khung hình video từ camera.
b. Phân tích văn bản
Phân tích văn bản (Text analysis) là công việc trích xuất hoặc phân lọi thông tin từ văn bản. Các văn bản ở đây có thể là các facebook posts, emails, các đoạn chats, tài liệu,… Một số ví dụ phổ biến là:
- Lọc spam (Spam filtering), là một trong những ứng dụng phân loại văn bản được biết và sử dụng nhiều nhất. Ở đây, phân loại văn bản là xác định chủ đề cho một văn bản. Bộ lọc spam sẽ học cách phân loại một email có phải spam không dựa trên nội dung và tiêu đề của email.
- Phân tích ngữ nghĩa (Sentiment Analysis), học cách phân loại một ý kiến là tích cực, trung tính hay tiêu cực dựa trên nội dung văn bản của người viết.
- Khai thác thông tin (Information Extraction), từ một văn bản, học cách để trích xuất các thông tin hữu ích. Chẳng hạn như trích xuất địa chỉ, tên người, từ khóa,…
c. Khai phá dữ liệu
Khai phá dữ liệu (Data mining) là quá trình khám phá ra các thông tin có giá trị hoặc đưa ra các dự đoán từ dữ liệu. Định nghĩa này có vẻ bao quát, nhưng bạn hãy nghĩ về việc tìm kiếm thông tin hữu ích từ một bảng dữ liệu rất lớn. Mỗi bản ghi sẽ là một đối tượng cần phải học, và mỗi cột là một đặc trưng. Chúng ta có thể dự đoán giá trị của một cột của bản ghi mới dựa trên các bản ghi đã học. Hoặc là phân nhóm các bản ghi của bản. Sau đây là những ứng dụng của khai phá dữ liệu:
- Phát hiện bất thường (Anomaly detection), phát hiện các ngoại lệ, ví dụ như phát hiện gian lận thẻ tín dụng. Bạn có thể phát hiện một giao dịch là khả nghi dựa trên các giao dịch thông thường của người dùng đó.
- Phát hiện các quy luật (Association rules), ví dụ, trong một siêu thị hay một trang thương mại điện tử. Bạn có thể khám phá ra khách hàng thường mua các món hàng nào cùng nhau. Dễ hiểu hơn, khách hàng của bạn khi mua món hàng A thường mua kèm món hàng nào? Các thông tin này rất hữu ích cho việc tiếp thị sản phẩm.
Ngoài ra, các thuật toán Học máy được sử dụng rộng rãi trong các bài toán như nận diện giọng nói (Search by text, talk to assitant like Siri hay Google Assistant), hệ thống khuyến nghị (ví dụ khi bạn tìm một sản phẩm nào đó trên Google thì sau đó trên các nền tảng xã hội mà bạn sử dụng sẽ xuất hiện một loạt các quảng cáo liên quan đến sản phẩm đó), xây dựng xe tự hành, dịch thuật, lọc email…
- Kết luận
Các thuật toán Học máy có nhiều ứng dụng to lớn giúp giải quyết các vấn đề phức tạp trong các lĩnh vực khác nhau. Bài viết này tổng hợp một số thông tin tổng quan về thuật toán. Chi tiết hơn về các thuật toán và cách sử dụng có thể dễ dàng tìm hiểu thông qua các bài giảng, khóa học và các nội dung được chia sẻ trên các nền tảng Internet. Trong các bài viết sau, chúng tôi sẽ tiếp tục giới thiệu từng thuật toán để bạn đọc có thêm nguồn tài liệu tham khảo cho các thuật toán này.
Nguyễn Hữu Du